

Seems like a weird segue, but as always, bear with me, there is (some) method to the madness.
Website news.
Six months into this idea of moving away from bigcorp (blogspot) to my own static website generator, I could not be happier.
I miss none of the features (?) of blogspot, the blog is better than it ever was, and I am quite glad I did not join stuff like Medium, Substack, CoHost, et al.
Most importantly though, I am having fun, even learning things.
My python code is terrible, and I could not care less. I just googled a couple of days ago "How do you divide your python code in multiple files" - unsurprisingly, you should use import - then still elected to ignore the advice and used exec(f.read()) instead, because YOLO!
So, I decided to add a journal section to the site. I always intended for this new site to lower (even more) the barrier of entry to my writing, and to be able to go back to real "blogging", not (just) long-form articles, but something more casual, more daily.
But something did not sit right with me, mixing in the same stream the two things. For a bit, I pondered the idea of adding some form of "tagging" to distinguish the two, but I was never fully persuaded.
Then, over the holiday break, while chilling on the beaches of Mexico, I had an idea! I like writing, a lot, and it is important to me to be able to always jot down notes and ideas...
I wanted the journal system to be similarly accessible, always, easily and asynchronosly, from everywhere I might be. What could fit the bill? E-mail!
 Mexico City and Tulum.
Mexico City and Tulum.Turns out that python has built-in support for IMAP and POP3. Emails are less obvious than you might think (well, if you, like me, have no experience with them), but in the end, the script that fetches mail from a special account, filters it, appends to a log, and marks the downloaded mails as deleted took something like a hundred LOCs.
You can have a peek at it here: journal_fetch.py
It took me longer to find a provider that would allow me to log in with a simple user/password combo, than writing the code itself! GMail does not allow that anymore (at all, you can't even generate an app-specific password AFAICT), Yahoo was supposed to, but the option for app passwords was disabled - you get the gist.
journal_fetch goes from email to a textual log, allowing to make edits trivially (unix-ish ideas!), then the website generator uses a subset of the tricks it employs to convert articles .txt into .htm, to make the journal section. Tada!
"Bad code".
Tinkering, with no expectation, in full, blissful ignorance. A.k.a. "end-user programming", the idea that non-experts should be able to write code, that personal computing itself should be about creating your own applications. For fun and profit.
This is what made a tiny thing like Microsoft: Basic, DOS, Excel (multiplan), Word - a perfect timeline if you think of it, giving people what they need to make things with "personal computing" (and in a way Azure is a perfect modern version, as the bulk of computing shifted to the cloud).
I won't go into a rant about what was lost, how computing became more passive and so on - both as I plan to write something later on - but also because I don't fully believe that. I don't subscribe to the Smalltalk philosophy of all code being hackable, I never liked Stallman's nor his ideology.
It's normal for technology, as it becomes of the masses, to become edulcorated - and even if in percentage, creators always tend to shrink relative to spectators (the "mass"), in absolute numbers both increase over time.
 Smalltalk, Dynabook - visionary and IMHO somewhat misguided ideas.
Smalltalk, Dynabook - visionary and IMHO somewhat misguided ideas.The early history of SmallTalk.
Andy Van Dam's I3D 2019 keynote. Alan Kay also has many interesting ones.
But what is the excuse for us, for programmers, not to tinker? Especially when it often takes longer to learn an existing (bloated, generic) system (and wrangle it to submit to our specifics) than to simply... write "bad code"!
"Bad code" is easy!
Good code, great code even can be "easy". Computer Science is, relatively speaking, not as hard as Computer Engineering - i.e. algorithms and data structures is not as complex, in practice, as the craft of programming in large teams for large, successful (and thus long-running) projects.
Mind, I'm not saying anything is easy. It's not easy to write the next state-of-the-art algorithm for... anything.
But relatively speaking, it is easier to do that, than maintain something entirely trivial, not novel and boring, that has a few million active users on it - as obviously evident by the fact that the former is typically the realm of the lone researcher, versus requiring a hierarchy with thousands engineers.
If you can, add some "bad code" to your life - you'll have fun.
Good architecture.
Is there anything real we can learn from this?
Is there a way to keep - for as long as we can, the "bad code" ethos (and its productivity, innovation), architecturally?
Not all bad code is made equal! I mean, without quotes, even truly bad code can be bad as in a skin tag, and bad as in a skin cancer. The former might be ugly, perhaps uncomfortable, but it can be excised at any time with minor surgery. The latter spreads, and if not removed early enough, ends up killing the host.
This is why I don't worry about the badness of my website code. The key parts of the website - the actual content - is so simple in its data format, that I could throw away everything, rewrite it in gw-basic tomorrow, and it would not take me more than a couple of days.
This is, in my view, the key role of good architecture. If your key components are isolated at the right level of granularity, and the interactions between them have a small, simple surface (API) - then badness can't spread.
Code should remain, for as long as possible, in chunks big enough to be useful, but small enough to be productive.
All of this is by no means novel.
Service-oriented architectures are the bread and butter of backend development, with all the debates over the right granularity (micro or macro services), API systems (serialization libraries).
Languages like Erlang support similar concepts natively, and even in client/C++/native-land we know code quality is related to the structure of dependencies.
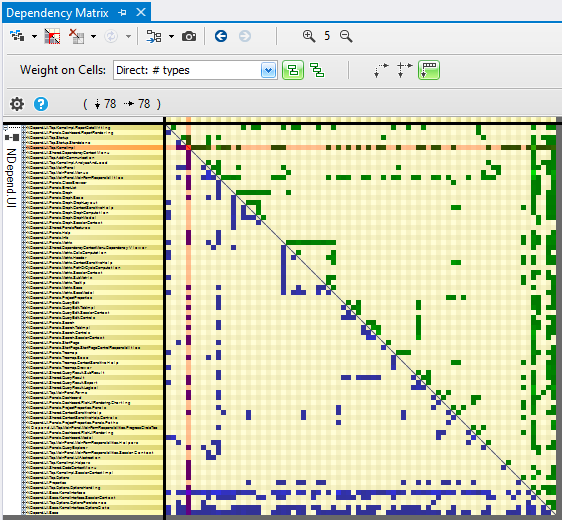 NDepend.
NDepend.Yet, in my experience, good architecture is relatively rare - probably due to two negative factors.
First, there is a widespread idea that "good code" is about sharing, reuse, and generalization. D.R.Y. et al, all the way down to how most languages are. The influence of OOP, the extremization of structured programming to the finest-grained elements of code, created a culture and practice of entanglement.
Think how easy it is to reuse functions all over the codebase, in any modern language. And think of whether or not there are any mechanisms to enforce the opposite - to avoid code spread.
In C/C++, I can decide to split my application into multiple projects, via libraries. I can even decide that certain sources should not ever be included in given projects and so on, but all these ideas are not at all part of the language.
Other languages might have more explicit support for modules and so on, but that does not mean it won't be easy, and encouraged even, to tangle dependencies.
And then, because the tangle is easy to break, we are encouraged to create isolated test environments, to gain back the benefits of isolation in artificial, useless code, that exists only to aid development! Mocking, TDD et al. Truly some terrible irony.
The second impediment to good architecture is that when it starts mattering, it's often too late, especially on successful projects. Early on, code is small, and small code does not require modularization, it's already productive and manageable by a small number of individuals.
If you have success though, you grow, and grow organically, over time. This is ideal: software - especially innovative ones, cannot be designed upfront and executed from scratch by a thousand people, that idea never works.
But the process also implies that at the point where (more) architecture needs to be added, it will always be through some degree of pain, as you will already have, inevitably, a "too big" team, a "too big" codebase, and enough success that production priorities will push against the needed refactoring.
Good architecture is the right amount of isolation. And the right amount of isolation, if you have success, tends to lag behind the size of your project.
Conclusions.
Am I saying we are destined to suffer? I believe so. The same as I believe that the right amount of (tech) debt is non-zero.
But that's not to say that everything is the same, because everything is bad. By now I hope you got what I mean. There is "bad" (that is actually good) and bad.
I did say that engineering is hard, didn't I?
 The joy of seeing the website on ever more improbable systems (plain DOS)!
The joy of seeing the website on ever more improbable systems (plain DOS)!